published by whitemice on Wed, 01/25/2023 - 11:03
Task: Converting an MBOX format export of a mailbox into a ZIP file containing each message as a file named after the message-id of the email message. Every e-mail client worth a pinch of salt can export messages, or a mailbox, to an MBOX file.
published by whitemice on Tue, 10/05/2021 - 08:43
KB5005573 broke our M$-Windows due to Windows' broken printing subsystem and Microsoft's refusal to migrate to Open solutions such as IPP & cupsd. Suddenly M$-Windows clients were failing to connect to printers with an extremely helpful and illuminating error code of 0x0000011b.
published by whitemice on Fri, 04/30/2021 - 09:11
Upgrading a Cisco AP, in this case a LAP1142N, from "lightweight" [not very useful] more to "Autonomous" [useful] mode. This assume the access point has been reset to factory defaults. For this example the AP is being upgraded to c1140-k9w7-mx.153-3.JBB.tar which is available on a tftp service @ 172.31.7.125.
published by whitemice on Fri, 12/11/2020 - 08:41
JSON is a strange format [I'm not a fan]. Opening a large JSON file in many text editors is unfruitful when the file is one long line - they will burn CPU trying to line wrap the data.
JSON however can be easily linted on the command line, producing a more friendly file.
cat onelongline.json | python -m json.tool > linted.json
And the file linted.json is readable and friendlier with text editors.
published by whitemice on Thu, 12/10/2020 - 14:58
I have a postfix SMTP relay buried deep in a network behind proxy servers, all the infrastructure [sadly] is IPv4 only. This works, yet one ends up with many log messages like:
connect to smtp.office365.com[2603:1036:304:2857::2]:587: Network is unreachable
The server attempts if IPv6 result from the DNS lookup first. So let's make postfix use IPv4 only.
postconf -e inet_protocols=ipv4
That's it! No more "unreachable" log messages.
published by whitemice on Fri, 12/04/2020 - 08:21
I went to start my Windows XP virtual machine, after something like ~4 years. And it failed to start with an 0x80004005 error: "Could not find the VirtualBox Report Desktop Extension library." Hmmm, that's strange.
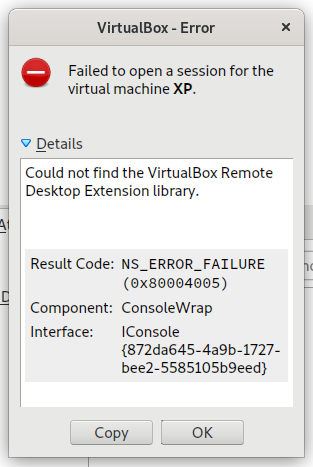
Turns out that the extensions loaded by the Windows XP VM uses the library libvncserver which was no longer installed on the host. Unfortunately the VirtualBox Extensions are not integrated into the distribution's package manager.
published by whitemice on Wed, 09/09/2020 - 14:06
Using lxml's etree to iteratively parse an XML document and I wanted to drop a specific element from the stream...
for event, element in etree.iterparse(self.rfile, events=("end",)):
if (event == 'end') and (element.tag == 'row'):
self.wfile.write(etree.tostring(element))
elif (event == 'end') and (element.tag == name_of_element_to_drop):
element.getparent().remove(element) # drop element
The secret sauce is: element.getparent().remove(element)
published by whitemice on Sun, 05/24/2020 - 14:52
Uh oh, in a default-ish GNOME install of openSUSE 15.1 there are a couple of unmatched / unclaimed dependencies. It appears Zoom Inc. did not try very hard when drafting the spec for their LINUX clients.
published by whitemice on Mon, 04/20/2020 - 13:21
In a few recent conversations I have become aware of an unawareness - an unawareness of the awesome that is gedit's best feature: External Tools. External Tools allow you to effortlessly link the power of the shell, Python, or whatever into an otherwise already excellent text editor yielding maximum awesome. External Tools, unlike some similar features in many IDEs is drop-dead simple to use - you do not need to go somewhere and edit files, etc...
published by whitemice on Mon, 11/25/2019 - 13:33
This is an update from "Uncoloring ls" which documents how to disable colored ls output on older systems which define that behavior in a profile.d script.
Pages